Современные технологии распознавания текста от Smart Engines
В последние годы технологии распознавания текста (OCR) переживают период стремительного развития. Компания Smart Engines занимает одно из лидирующих мест в этой области, предлагая инновационные решения, которые значительно повышают точность и скорость обработки данных. Подробности о последних достижениях можно найти по ссылке https://www.c-inform.info/news/id/112524. Их нейросетевые алгоритмы способны работать с различными типами документов, включая паспорта, водительские удостоверения и банковские карты.
Главное преимущество инноваций Smart Engines заключается в использовании глубинного обучения и адаптивных нейросетей, которые способны учитывать особенности шрифтов, износа документов и искажения изображений. Это существенно снижает количество ошибок при распознавании и минимизирует необходимость ручной доработки. В результате клиенты получают быстрый и надежный инструмент для автоматизации обработки документов в самых разных сферах — от банковского сектора до государственных учреждений.
Преимущества использования нейросетей в OCR-системах
Использование нейросетевых технологий в системах оптического распознавания текста открывает новые горизонты. Нейросети способны самостоятельно обучаться на большом количестве данных, что позволяет им адаптироваться к самым разнообразным сценариям использования. Smart Engines активно внедряет эти технологии, что обеспечивает высокую устойчивость к шуму, плохому качеству фото и различным искажениям.
Нейросетевые модели, применяемые компанией, обладают следующими важными преимуществами:
- Быстрая обработка больших объемов данных с минимальными затратами ресурсов;
- Высокая точность распознавания даже нечетких или плохо отсканированных документов;
- Гибкость в интеграции с различными платформами и системами;
- Автоматическое улучшение модели благодаря постоянному обучению и обновлениям.
Все это делает технологии Smart Engines особенно востребованными в сегментах, где требуются надежность и высокая скорость обработки информации, например, в финансовой сфере и электронном документообороте.
Интеграция нейросетевых решений Smart Engines в бизнес-процессы
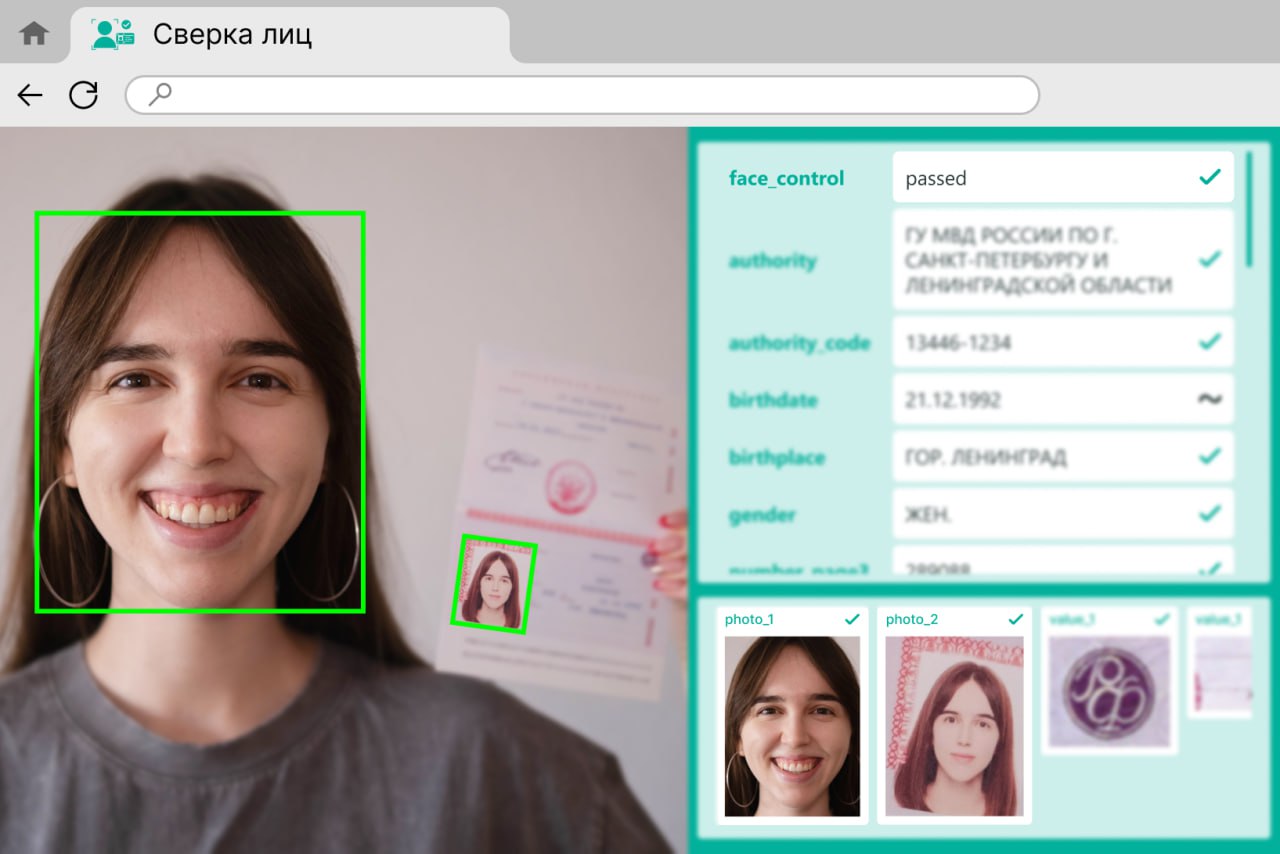
Для успешной автоматизации документооборота важно не только иметь качественный распознаватель текста, но и грамотно интегрировать его в существующие бизнес-процессы. Smart Engines предлагает комплексный подход, что обеспечивает максимально гладкую интеграцию нейросетевых моделей в корпоративные системы клиентов.
Компания предоставляет гибкие API и SDK, которые позволяют настроить распознавание под конкретные задачи, будь то контроль качества документов или ускорение обработки заявок. Это значительно уменьшает нагрузку на специалистов и повышает общую эффективность работы организации.
Особое внимание уделяется безопасности данных и защите конфиденциальной информации, что особенно актуально в банковской сфере и госструктурах. Нейросети Smart Engines обрабатывают данные локально или в защищенных облачных средах, исключая риск утечки информации.
Таким образом, внедрение технологий Smart Engines становится ключевым фактором цифровой трансформации бизнеса, снижая операционные издержки и повышая качество обслуживания клиентов.
Будущее OCR и роль Smart Engines в развитии технологий
Перспективы развития технологий распознавания текста связаны с углублением использования искусственного интеллекта и машинного обучения. Smart Engines продолжает активно инвестировать в исследовательские проекты, совершенствуя свои нейросетевые модели и расширяя функционал. Это позволяет создавать продукты, способные распознавать тексты на множестве языков, включая редкие и специализированные шрифты, а также интегрировать технологии в мобильные приложения и облачные сервисы.
Компания планирует фокусироваться на автоматизации сложных сценариев, таких как распознавание рукописного текста и документов с нестандартной разметкой. Такой подход позволит значительно расширить сферы применения OCR — от медицины до логистики.
В итоге, инновации Smart Engines в области нейросетей для распознавания текста не просто улучшают существующие решения, но и закладывают фундамент для новых возможностей и стандартов в цифровой обработке информации, что обещает сделать работу с текстовыми данными максимально простой и эффективной.